
GET STARTED
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Deep dives into contextual robustness, synthetic data, and red teaming methods for high-stakes visual AI systems.
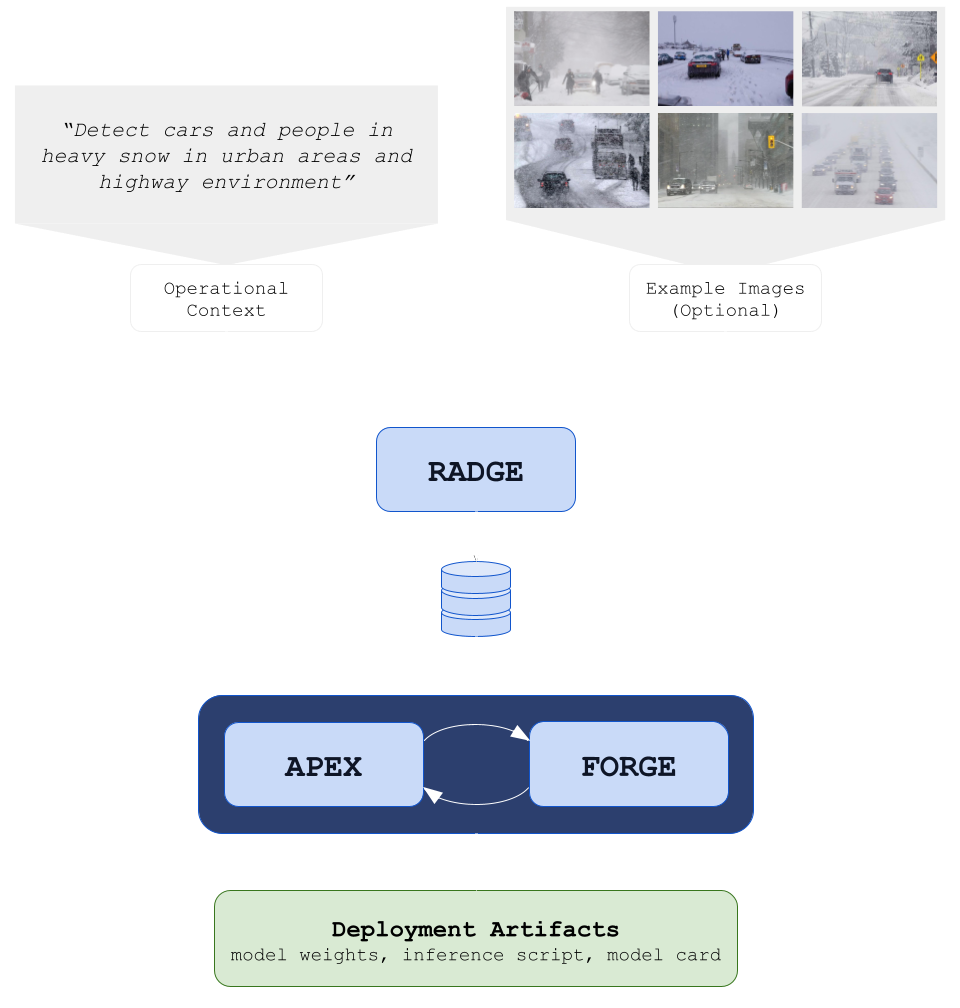
Yrikka’s Text-to-Model (T2M) removes the data bottleneck in real-world vision by generating long-tail scenarios, training multiple candidate models, and stress-testing them automatically. Powered by RADGE for realistic data generation, APEX for scenario-matched evaluation and red-teaming) and FORGE for agentic training and model selection, T2M turns a natural-language idea and a few images into a deployable model.
Every real-world vision system eventually meets the same obstacle: data. Not just the amount, but the kind that truly reflects the long tail: rare, messy, and unpredictable cases that determine whether a model works outside the lab. Capturing and labeling enough of these examples is slow, expensive, and often impractical. Teams spend most of their time managing data pipelines instead of improving models. Once the data barrier is lifted, model building becomes a structured process. With reliable and representative data, AI agents can handle much of the training and evaluation loop automatically, testing hypotheses faster than any manual cycle could.
Yrikka’s Text-to-Model (T2M) is built around this idea. Starting from a few unlabeled images and a natural-language description, T2M generates the data, trains multiple candidate models, and evaluates them under realistic conditions. This is achieved by three coordinated Yrikka services: RADGE for generating realistic data that covers the long-tails, APEX for scenario-matched evaluation and red-teaming, and FORGE, an agentic training system that coordinates fine-tuning and model selection, completing the loop from concept to deployment.
ML teams consistently report that data collection and labeling dominate project time and budget. Surveys often find that roughly 80% of ML development effort goes into data work before modeling even begins. Data‑centric AI reframed progress around systematic improvements in datasets and label quality rather than endless architecture tweaks. In particular, small upstream data issues compound downstream into reliability failures [1].
Collecting representative data is expensive. It must span weather, time of day, motion blur, and long‑tail events. In safety‑critical domains (e.g., AV, autonomous drones), capturing edge cases is costly, risky, and statistically intractable: demonstrating safety through public‑road testing alone would require hundreds of millions to billions of miles, and real‑world testing “places the public in danger,” making advanced simulation essential [2]. Even when data is available, labeling costs stack up quickly. Typical pricing for annotation range from $0.02–$1.00 per bounding box and $0.05–$3.00 per mask, with specialized annotations much higher for complex tasks; at the frontier, single expert annotations can cost tens of dollars or more.
Traditional simulation and game‑engine pipelines often suffer a sim‑to‑real gap: models that excel on synthetic data underperform on real imagery without extensive manual tuning. Closing this gap typically requires deep domain expertise and significant effort. [3]
Diffusion models challenge this paradigm. They produce highly realistic samples and can be steered by text, layout, or segmentation conditioning. For example, the FLUX family and its variants demonstrate strong photo‑realism and fast generation at high resolution [4]. Multiple studies show diffusion‑generated data can improve object detection and segmentation performance, especially in low‑data or long‑tail regimes [5]. But realism alone isn’t enough. How do we ensure the images cover the long tail, match our sensors, and arrive with trustworthy labels?
RADGE (Retrieval Augmented Data Generation Engine) learns your domain from a few example images and a brief natural‑language spec.
The output is scalable, labeled multi-modal (e.g., EO/IR) data matched to your optics and environment.
With RADGE producing sensor-matched, labeled data on demand, the bottleneck shifts from data collection and processing to model iteration. These model iterations can be automated with AI agents. ML engineer (MLE) agents are increasingly capable of executing well-structured ML engineering tasks autonomously. Results from OpenAI’s MLE-Bench show that such agents can achieve top 10% performance among ML teams on Kaggle-style tasks [6].
Yrikka’s Text-to-Model framework treats model training as an engineering loop: propose, run, measure, and iterate. The multi-agent framework, FORGE (Fine-tuning Orchestrator for Robust Generalization and Evaluation) launches candidate model backbones (e.g., YOLOv11, DETR, Faster R-CNN), tunes hyperparameters, blends synthetic with any real data you provide, and evaluates models with the Yrikka APEX API. APEX (Adversarial Probing & Evaluation of Exploits) automates model eval and red-teaming [7], enabling optimization against scenario‑matched metrics rather than global averages.
With data generation and training automated end-to-end, here’s what that translates to for your team:
Adverse weather remains one of the most persistent challenges in autonomous perception. Snow, fog, and rain degrade visibility, distort textures, and confuse models trained predominantly on clear-day imagery. These conditions account for a significant portion of real-world failures in automated driving systems (ADS) and autonomous vehicles (AVs). Yet collecting such data is logistically demanding. It often requires travel to specific regions or seasons, specialized sensors, and safety-constrained operations in difficult conditions.
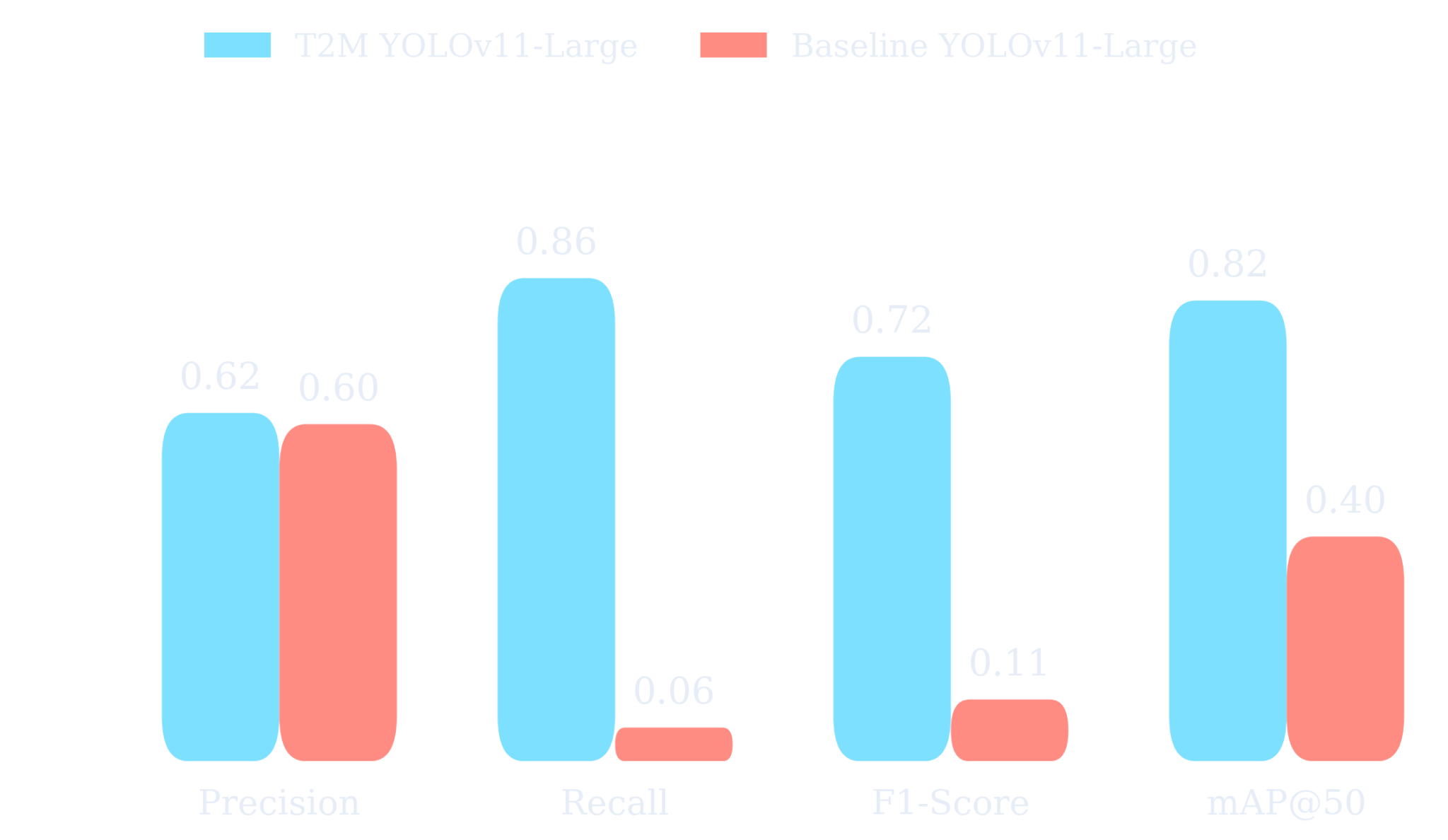
To explore how Text-to-Model (T2M) can address this gap, we applied it to detection of people and cars in heavy snow. Starting from a handful of unlabeled reference images and a brief textual description of the scenario, T2M generated sensor-matched synthetic data, trained multiple model candidates, and automatically selected the best performer for deployment. We then evaluated the resulting model on DAWN, a public benchmark of 1,000 real‑world traffic images captured in fog, snow, rain, and sandstorms, annotated with bounding boxes for the car and the person class across varied road scenes (urban, highway, freeway).
For this experiment, T2M selected YOLOv11-Large as the optimal architecture for the task. As shown below, the fine-tuned model substantially improved recall and mean average precision (mAP@50) under snow conditions compared to its pretrained counterpart. The confusion matrices further highlight reduced false negatives for both person and car classes, demonstrating that domain-matched synthetic data and agentic fine-tuning can meaningfully enhance model reliability in operationally challenging environments.
Building vision systems that hold up in the real world has always hinged on two things: having the right data and moving fast enough to use it effectively. Yrikka’s Text-to-Model brings those pieces together. RADGE removes the data bottleneck by producing realistic, labeled samples matched to the user’s domain. APEX ensures models are tested under meaningful, condition-matched scenarios. And FORGE closes the loop, coordinating the training, fine-tuning, and selection of models through an adaptive agentic framework.
Together, they form a unified workflow where data, modeling, and evaluation inform one another in real time. The result is not a shortcut, but a more direct path from concept to a dependable, deployment-ready model.
[1] Sambasivan, Nithya, et al. "“Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI." Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 2021.
[2] Kalra, Nidhi, and Susan M. Paddock. "Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability?." Transportation research part A: policy and practice 94 (2016): 182-193.
[3] Sudhakar, Sruthi, et al. "Exploring the sim2real gap using digital twins." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[5] Fang, Haoyang, et al. "Data augmentation for object detection via controllable diffusion models." Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2024.
[6] Chan, Jun Shern, et al. "Mle-bench: Evaluating machine learning agents on machine learning engineering." arXiv preprint arXiv:2410.07095 (2024).
[7] https://github.com/YRIKKA/apex-quickstart
We’re always looking for exceptional ML engineers and researchers. If you thrive at the boundary of foundation models, simulation, and robust evaluation, we’d love to meet you.